
Explanation:
The senior engineer's concern highlights a critical oversight: the current approach only removes duplicates within the streaming state, not against the target table's existing data. This means late-arriving duplicates could bypass detection. Watermarking (B) is also crucial as it defines how long Spark retains state for deduplication, ensuring late data within a specified window is considered. While a ranking function (A) and window function (C) offer additional controls, they're not the primary solution here. The scenario provides sufficient context, making (E) unnecessary.
Ultimate access to all questions.
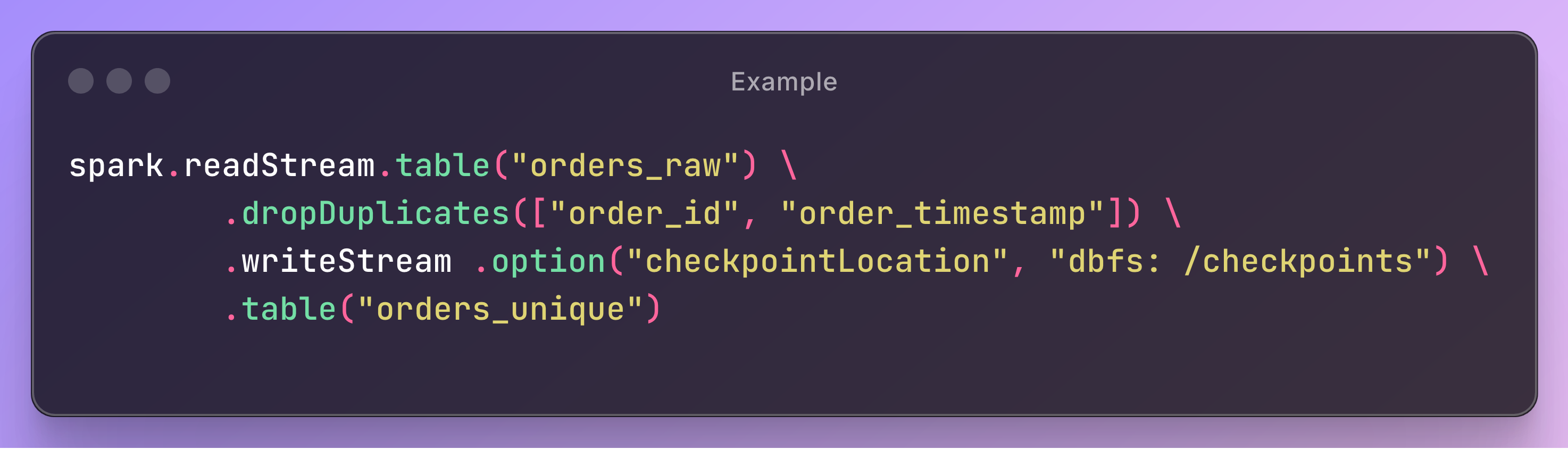
A junior data engineer is using the following code to de-duplicate raw streaming data and insert them into a target Delta table.
spark.readStream.table("orders_raw") \
.dropDuplicates(["order_id", "order_timestamp"]) \
.writeStream .option("checkpointLocation", "dbfs: /checkpoints") \
.table("orders_unique")
spark.readStream.table("orders_raw") \
.dropDuplicates(["order_id", "order_timestamp"]) \
.writeStream .option("checkpointLocation", "dbfs: /checkpoints") \
.table("orders_unique")
However, a senior data engineer points out that this approach may not suffice for ensuring distinct records in the target table, especially with late-arriving duplicates. What could explain the senior engineer's concern?
A
Implementing a ranking function is necessary to process only the most recent records.
B
Watermarking is required to track state information within a specific time window, accommodating delayed records.
C
The solution lacks a window function to apply deduplication across non-overlapping intervals.
D
New records must be deduplicated against existing data in the target table to prevent duplicates.
E
Additional information is necessary to accurately address the issue.
No comments yet.