Explanation:
The correct sequence for a RAG-enabled chatbot workflow is: 1. Embedding model (converts the user's question into vector representation), 2. Vector search (finds relevant documents using the vector), 3. Context-augmented prompt (combines retrieved context with the original question), and 4. Response-generating LLM (produces the final answer). This sequence is supported by the community discussion, where option A received 100% consensus and upvoted comments explained that the embedding model must come first to vectorize the question, followed by vector search to retrieve relevant context, then context augmentation, and finally the LLM for response generation. Options B, C, and D are incorrect because they either place the LLM too early (C and D) or misorder the vector search and context augmentation steps (B), disrupting the logical flow of retrieving context before generating a response.
Ultimate access to all questions.
No comments yet.
Based on the diagram, what is the correct sequence of components that a user's question passes through in a RAG-enabled chatbot before the final output is returned?
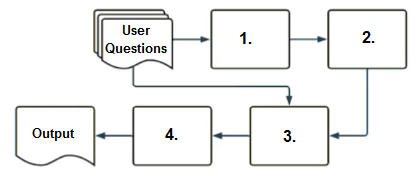
A
1.embedding model, 2.vector search, 3.context-augmented prompt, 4.response-generating LLM
B
1.context-augmented prompt, 2.vector search, 3.embedding model, 4.response-generating LLM
C
1.response-generating LLM, 2.vector search, 3.context-augmented prompt, 4.embedding model
D
1.response-generating LLM, 2.context-augmented prompt, 3.vector search, 4.embedding model