Explanation:
The correct answer is B.
The result set shows:
group_1 and group_2 (e.g., A+Y, A+Z, B+Y, B+Z).group_1 (rows where group_2 is null: A null = 50, B null = 50).group_2 (there is no row like null + Y or null + Z as a subtotal).group_1 and group_2 are null = 100).This pattern is exactly what GROUP BY group_1, group_2 WITH ROLLUP produces in Databricks/Spark SQL.
ROLLUP on (col1, col2) generates these grouping sets automatically:
(group_1, group_2) → detailed rows(group_1) → subtotals by group_1 (sets group_2 = null)() → grand total (both columns null)It follows the left-to-right hierarchy of the columns listed. It does not create the cross-subtotal (group_2) alone (i.e., no independent group_2 subtotals with group_1 = null).
A: INCLUDING NULL is not valid Databricks SQL syntax for GROUP BY.
C: Plain GROUP BY group_1, group_2 returns only the detailed combinations. It produces no subtotal or grand total rows (no null rows at all).
D: Invalid/non-standard syntax. Grouping by the tuple (group_1, group_2) again does not create subtotals or grand totals.
E: WITH CUBE generates all possible combinations (full cross-tab):
(group_1, group_2)(group_1)(group_2) ← extra rows (null + Y, null + Z)()The provided result is missing the (group_2) subtotal rows, so it cannot be CUBE.
| Operator | Grouping sets generated for (col1, col2) | When to use |
|---|---|---|
| Plain GROUP BY | Only (col1, col2) | Basic aggregation |
| WITH ROLLUP | (col1,col2) + (col1) + () | Hierarchical subtotals |
| WITH CUBE | (col1,col2) + (col1) + (col2) + () | All combinations / cross-tabs |
| GROUPING SETS | Whatever you explicitly list | Full control |
The table in the question has zero original NULLs, so all null values in the output are super-aggregate markers created by ROLLUP.
Ultimate access to all questions.
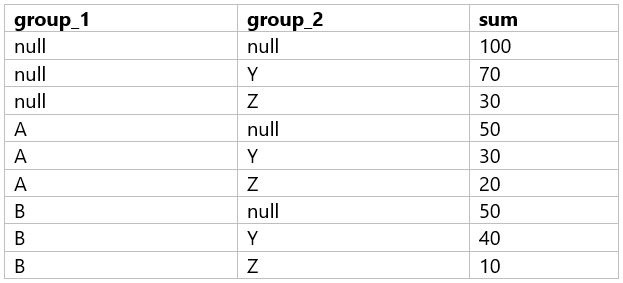
A data analyst is processing a complex aggregation on a table with zero null values and their query returns the following result:
| group_1 | group_2 | sum |
|---|---|---|
| null | null | 100 |
| null | Y | 70 |
| null | Z | 30 |
| A | null | 50 |
| A | Y | 30 |
| A | Z | 20 |
| B | null | 50 |
| B | Y | 40 |
| B | Z | 10 |
Which of the following queries did the analyst run to obtain the above result?
A
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2 INCLUDING NULL;
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2 INCLUDING NULL;
B
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2 WITH ROLLUP;
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2 WITH ROLLUP;
C
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2;
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2;
D
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2, (group_1, group_2);
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2, (group_1, group_2);
E
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2 WITH CUBE;
SELECT
group_1,
group_2,
count(values) AS count
FROM my_table
GROUP BY group_1, group_2 WITH CUBE;