Explanation:
The error in the code block is that the return type of the UDF is not specified. In Spark Scala UDFs, when the return type is not a basic type that Spark can infer automatically (like String in this case), it's recommended to explicitly specify the return type using the second parameter of the udf() function. While Spark might sometimes infer String types, explicitly specifying the return type is considered a best practice for clarity and to avoid potential runtime issues. Option A is incorrect because the input type is specified as Int in the function definition. Option C is wrong because withColumn() is the appropriate way to apply UDFs in DataFrames. Option D is incorrect because UDFs can be defined directly without first creating a Scala function. Option E is wrong because UDFs can be applied through both SQL and DataFrame API.
Ultimate access to all questions.
No comments yet.
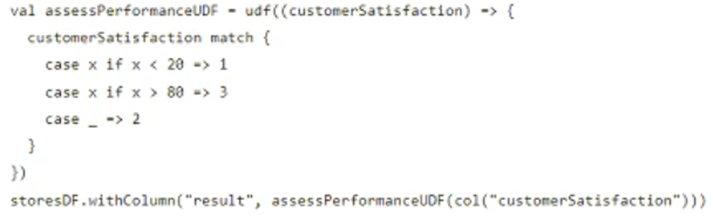
The code block shown below contains an error. The code block is intended to create the Scala UDF assessPerformanceUDF() and apply it to the integer column customerSatisfaction in DataFrame storesDF. Identify the error.
Code block:
val assessPerformanceUDF = udf( (score: Int) => {
if (score > 8) "High"
else if (score > 5) "Medium"
else "Low"
})
storesDF.withColumn("performance", assessPerformanceUDF(customers1t1sfaction))
val assessPerformanceUDF = udf( (score: Int) => {
if (score > 8) "High"
else if (score > 5) "Medium"
else "Low"
})
storesDF.withColumn("performance", assessPerformanceUDF(customers1t1sfaction))
A
The input type of customerSatisfaction is not specified in the udf() operation.
B
The return type of assessPerformanceUDF() must be specified.
C
The withColumn() operation is not appropriate here - UDFs should be applied by iterating over rows instead.
D
The assessPerformanceUDF() must first be defined as a Scala function and then converted to a UDF.
E
UDFs can only be applied via SQL and not through the Data Frame API.