Explanation:
Option C is correct because it properly uses the split function with col() to reference the column, and correctly accesses array elements [0] and [1] to extract the first and second parts of the split string. The community discussion shows consensus for C, with the highest upvoted comments supporting it. While some comments mention D might work in newer Spark versions (3.5+), the exam is based on Spark 3.0 where split requires column references using col(). Option A and E incorrectly use array indices [1] and [2] which would skip the first element. Option B incorrectly uses col().split() syntax instead of split(col()). Option D uses split with string literals instead of column references, which is incorrect for Spark 3.0.
Ultimate access to all questions.
No comments yet.
Which of the following code blocks splits the storeCategory column from DataFrame storesDF at the underscore character into two new columns named storeValueCategory and storeSizeCategory?
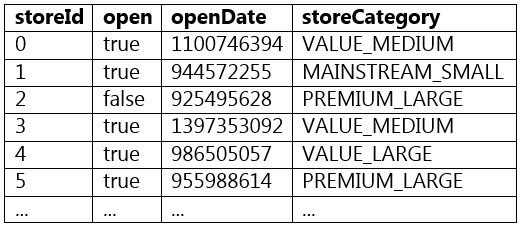
A sample of DataFrame storesDF is displayed below:
//IMG//
A
(storesDF.withColumn("storeValueCategory", split(col("storeCategory"), "")[1]) .withColumn("storeSizeCategory", split(col("storeCategory"), "")[2]))
B
(storesDF.withColumn("storeValueCategory", col("storeCategory").split("")[0]) .withColumn("storeSizeCategory", col("storeCategory").split("")[1]))
C
(storesDF.withColumn("storeValueCategory", split(col("storeCategory"), "")[0]) .withColumn("storeSizeCategory", split(col("storeCategory"), "")[1]))
D
(storesDF.withColumn("storeValueCategory", split("storeCategory", "")[0]) .withColumn("storeSizeCategory", split("storeCategory", "")[1]))
E
(storesDF.withColumn("storeValueCategory", col("storeCategory").split("")[1]) .withColumn("storeSizeCategory", col("storeCategory").split("")[2]))