Explanation:
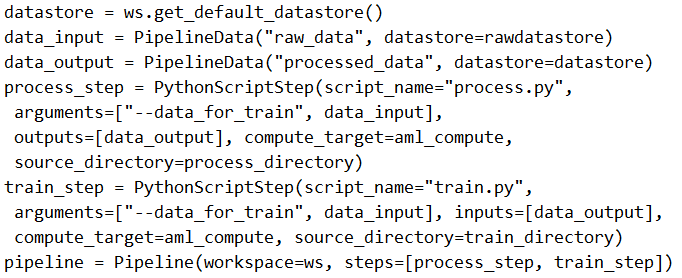
The solution does NOT meet the goal because there are two critical issues in the training step: (1) The arguments parameter incorrectly references 'processed_data' directly instead of using the PipelineData object's output path, which should be accessed via the script's command-line argument parsing. In Azure ML pipelines, PipelineData objects represent intermediate data paths that need to be properly passed to scripts. (2) The community discussion (with comments receiving 7 and 5 upvotes) confirms that the arguments configuration is incorrect, noting that 'arguments=["--input", processed_data]' is not the proper way to pass PipelineData between steps. The correct approach would involve using the PipelineData object as both an output in the processing step and an input in the training step, with proper argument handling in the scripts themselves.
Ultimate access to all questions.
No comments yet.
You create a model to forecast weather conditions based on historical data. You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script.
Solution: Run the following code:
from azureml.core import Workspace, Dataset, Experiment
from azureml.core.runconfig import RunConfiguration
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.pipeline.steps import PythonScriptStep
# Define data reference
raw_data = Dataset.get_by_name(ws, 'raw_weather_data')
processed_data = PipelineData('processed_data', datastore=ws.get_default_datastore())
# Define processing step
process_step = PythonScriptStep(
name='process_data',
script_name='process.py',
arguments=['--input', raw_data.as_named_input('input'), '--output', processed_data],
inputs=[raw_data],
outputs=[processed_data],
compute_target=compute_target,
runconfig=run_config
)
# Define training step
train_step = PythonScriptStep(
name='train_model',
script_name='train.py',
arguments=['--input', processed_data],
inputs=[processed_data],
compute_target=compute_target,
runconfig=run_config
)
# Create and run pipeline
pipeline = Pipeline(workspace=ws, steps=[process_step, train_step])
pipeline_run = Experiment(ws, 'weather_forecast').submit(pipeline)
from azureml.core import Workspace, Dataset, Experiment
from azureml.core.runconfig import RunConfiguration
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.pipeline.steps import PythonScriptStep
# Define data reference
raw_data = Dataset.get_by_name(ws, 'raw_weather_data')
processed_data = PipelineData('processed_data', datastore=ws.get_default_datastore())
# Define processing step
process_step = PythonScriptStep(
name='process_data',
script_name='process.py',
arguments=['--input', raw_data.as_named_input('input'), '--output', processed_data],
inputs=[raw_data],
outputs=[processed_data],
compute_target=compute_target,
runconfig=run_config
)
# Define training step
train_step = PythonScriptStep(
name='train_model',
script_name='train.py',
arguments=['--input', processed_data],
inputs=[processed_data],
compute_target=compute_target,
runconfig=run_config
)
# Create and run pipeline
pipeline = Pipeline(workspace=ws, steps=[process_step, train_step])
pipeline_run = Experiment(ws, 'weather_forecast').submit(pipeline)
Does the solution meet the goal?
A
Yes
B
No