
Explanation:
We have two fact tables (Flight and Weather) that will be frequently joined on airport-related columns. In Azure Synapse Analytics (formerly SQL Data Warehouse), the distribution strategy is critical for query performance, especially for join operations.
Option B is the correct recommendation because:
Option A (Hash distribution on datetime columns):
Option C (IDENTITY columns):
Option D (Composite columns):
In Azure Synapse Analytics, the fundamental principle for optimizing join performance is to distribute both tables on the same join column using hash distribution. This strategy minimizes data movement across the distributed architecture, which is the primary performance bottleneck in large-scale data processing systems.
No comments yet.
You have two fact tables named Flight and Weather. Queries will join these tables on the following columns:
Flight Table | Weather Table
------------------|-----------------
DepartureDate | Date
DepartureAirport | AirportCode
Flight Table | Weather Table
------------------|-----------------
DepartureDate | Date
DepartureAirport | AirportCode
You need to recommend a solution that maximizes query performance. What should you include in the recommendation?
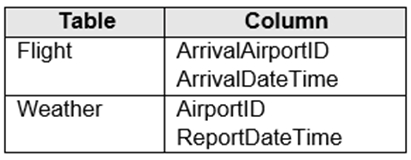
A
In the tables use a hash distribution of ArrivalDateTime and ReportDateTime.
B
In the tables use a hash distribution of ArrivalAirportID and AirportID.
C
In each table, create an IDENTITY column.
D
In each table, create a column as a composite of the other two columns in the table.