
Explanation:
For a large fact table in Azure Synapse Analytics with over 1 billion rows (1 million daily × 3 years), the optimal distribution strategy must consider data volume, query patterns, and performance characteristics.
Why this is optimal:
Performance Benefits:
Option A: Replicated
Option C: Round-robin
Option D: Hash-distributed on IsOrderFinalized
While the query doesn't directly use PurchaseKey in GROUP BY or WHERE clauses, hash distribution on a high-cardinality column like PurchaseKey provides the foundation for efficient parallel processing. The system can still leverage the even data distribution to optimize the GROUP BY operations on SupplierKey, StockItemKey, and IsOrderFinalized.
Conclusion: Hash distribution on PurchaseKey provides the most balanced and scalable approach for this large fact table scenario, aligning with Azure Synapse Analytics best practices for data warehousing workloads.
No comments yet.
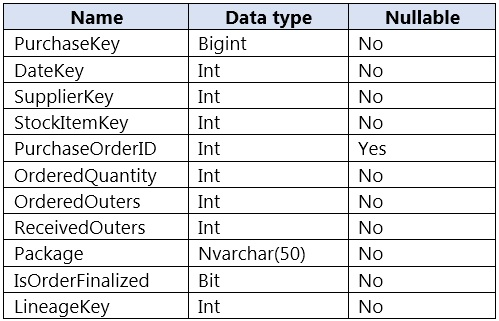
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool for a retail store. The table will contain purchase data from suppliers with the following columns:
PurchaseKeySupplierKeyStockItemKeyDateKeyIsOrderFinalizedThe table will have 1 million rows added daily and will store three years of data. Daily queries will be executed that are similar to the following:
SELECT
SupplierKey,
StockItemKey,
IsOrderFinalized,
COUNT(*)
FROM FactPurchase
WHERE DateKey >= 20210101
AND DateKey <= 20210131
GROUP BY
SupplierKey,
StockItemKey,
IsOrderFinalized
SELECT
SupplierKey,
StockItemKey,
IsOrderFinalized,
COUNT(*)
FROM FactPurchase
WHERE DateKey >= 20210101
AND DateKey <= 20210131
GROUP BY
SupplierKey,
StockItemKey,
IsOrderFinalized
Which table distribution type will minimize query times?
A
replicated
B
hash-distributed on PurchaseKey
C
round-robin
D
hash-distributed on IsOrderFinalized